微软战略大转变:拥抱小模型!如何助力企业创新发展?

撰稿 | 言征
出品 | 51CTO技术栈(微信号:blog51cto)
微软的生成式AI战略似乎出现了180度大转变:相比大模型,小模型才是微软的真爱。
在Ignite 2023上,微软董事长兼首席执行官Nadella在主题演讲中表示:“微软喜欢小模型(SLM)”,并宣布了名为Phi-2的Phi小型语言模型(SLM)系列的最新迭代。
Nadella表示,这款由微软研究部在高度专业化的数据集上开发的Phi-2,可以与150倍大的模型相媲美。
重要的是,许多企业伙伴也认为如此,他们认为与大型语言模型(LLM)相比,较小的模型对企业更有用。
1、微软推出小模型,由来已久今年早些时候,除了发布Phi和Phi 1.5,微软还发布了Ocra,这是一个基于Vicuna的130亿参数的开源模型,可以模仿和学习GPT-4大小的LLM。
今年,6 月,微软发布了一篇题为《Textbooks Are All You Need》的论文,用规模仅为 7B token 的「教科书质量」数据训练了一个 1.3B 参数的模型 ——Phi-1。尽管在数据集和模型大小方面比竞品模型小几个数量级,但 phi-1 在 HumanEval 的 pass@1 上达到了 50.6% 的准确率,在 MBPP 上达到了 55.5%。
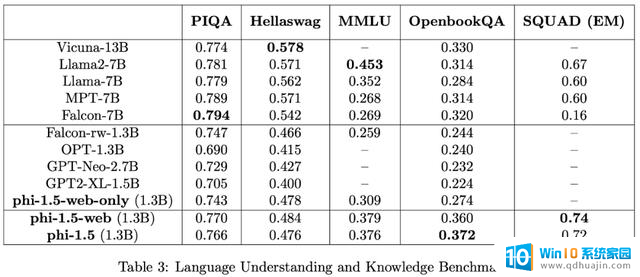
Phi-1 证明高质量的「小数据」能够让模型具备良好的性能。9月,微软又发表了论文《Textbooks Are All You Need II: phi-1.5 technical report》,对高质量「小数据」的潜力做了进一步研究。Phi-1.5 的架构与 phi-1 完全相同,有 24 层,上下文长度为 2048,实验结果显示,对于语言理解任务,在多个数据集(包括 PIQA、Hellaswag、OpenbookQA、SQUAD 和 MMLU)上,Phi-1.5 的性能可以媲美 5 倍大的模型,甚至在在更复杂的推理任务(例如小学数学和基础编码任务)上 Phi-1.5 还超越了大多数 LLM,以至于人们开始质疑该模型是不是用了测试集来训练。
图片
据微软官网介绍,Phi-2是一款具有27亿参数的Transformer。与Phi-1-5相比,它在推理能力和安全措施方面有了显著改进,与常识、语言理解和逻辑推理等基准测试参数相比,表现出了最先进的性能。
与行业中的其他Transformer相比,它体积更轻更小。通过正确的微调和定制,这些小模型对于云和边缘应用程序来说都是非常强大的工具。
2、小模型正在兴起在过去一年左右的时间里,大模型吸引了全球的注意力,从GPT3.5、GPT-4、PaLM-2到Falcon和LLaMA等开源模型。然而,种种迹象表明,小模型如今越来越受到重视。
首先,当Meta发布LLaMA时,它有四种变体——70亿、130亿、330亿和650亿,至少在某种意义上预示着小模型的发展。它促使人们认识到,参数较少的小型模型可以表现得令人钦佩。
如今微软公开表示“喜欢”小模型,更是佐证了这一趋势。
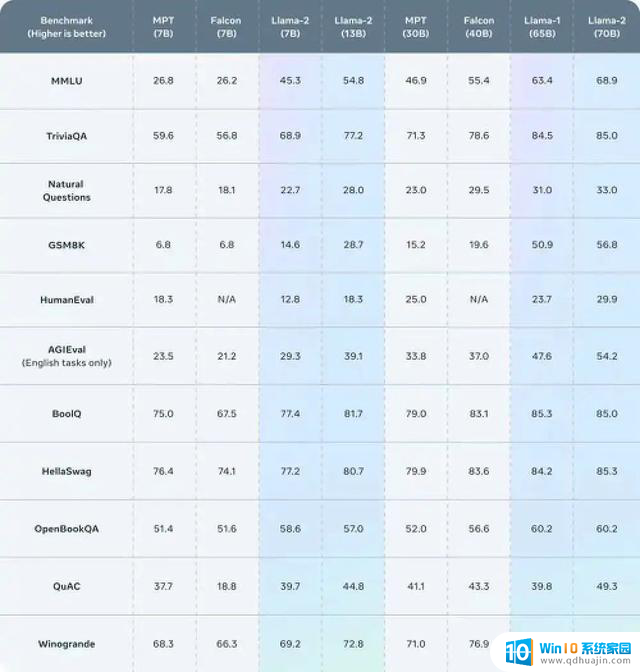
考虑到LLM的训练成本高昂,这是采用LLM的主要障碍之一。与GPT-3.5和GPT-4相比,较小的型号显著节省了成本。LLaMA 2有三种变体——70亿、130亿和700亿——生成段落摘要的费用大约是GPT-4的30倍,同时保持了同等的准确性。较小的模型不仅具有成本效益,而且在准确性方面也很出色。与在庞大多样的数据集上训练的大型模型不同,小型模型专注于根据特定业务用例量身定制的经过仔细审查的数据,以确保准确性和相关性。
图片
Llama 2 在许多外部基准测试上都优于其他开源语言模型,包括推理、编码、熟练程度和知识测试。
HuggingFace首席执行官Clem Delangue预测:“大多数公司都会意识到,更小、更便宜、更专业的模型对99%的人工智能用例更有意义。”OpenAI的首席执行官Sam Altman也表达了这种观点。
在麻省理工学院的一次讨论中,Altman设想了一个参数数量减少的未来,一组较小的模型优于较大的模型。微软在开发小型机型方面的努力强调了他们对小模型未来将为企业带来重大利益的信念。
3、企业更喜欢小模型对于B端市场而言,之前在《企业版ChatGPT,基本凉了!》一文中就提到了,大模型很难解决的问题:如何保护企业的私有数据不被泄露和利用,让企业的核心数据资产暴露给通用大模型基本上是不可能的。
这有就意味着基于公有云的大模型很难在短时间内取得企业的信任。即便大家一致认为,生成式AI在提升决策、创新和运营效率方面起着越来越重要的作用,但如果存在着把数字命脉交出去的可能性,显然也是不妥的。
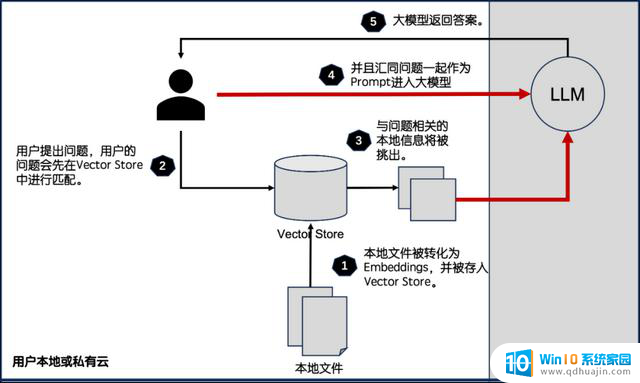
比如,最近大火的大模型开源调度框架、估值超过2亿美元Langchain机制,就展示了这种威胁。在Langchain机制的第3、4步中,其先将问题和相关本地数据资产打包形成Prompt,然后再将Prompt通过API传给远程的大模型以获取答案。在传输的过程中和上传的大模型后,企业的数据资产都存在泄露的可能性。
图片
这样看来,出于数据安全和隐私的考虑,一个本地化的大模型方案似乎是必然的。但是,企业客户能否负担得起私有的通用大模型?高昂的成本和算力的封禁政策,都是不太可能短期解决的。
所以小模型似乎成了一种更实用的企业版方案,小模型的定制成本或许依然不菲,但对于取得获得收益而言,是可负担的。
4、微调模型的完美之选,也许在挑战Llama在Ignite 2023期间,Nadella还推出了“模型即服务(MaaS)”产品,为企业提供了在Hugging Face等平台上访问各种开源模型的机会,包括Mistral和Llama 2的模型。

图片
此外,Azure AI目录中的企业也可以使用Phi-2,它也可以被视为LLaMA系列模型的竞争者。今年早些时候,微软已经声称,拥有13亿参数的Phi-1.5在几个基准上优于LlaMA 2的70亿参数模型。
当Llama向公众发布时,它既没有人的反馈强化学习(RLHF),也没有指导或对话调整。然而,它的开源性质在社区内引发了高度热情,导致了一系列变体,包括指令调整、人工评估、多模态、RLHF等。它使Llama成为最受欢迎的型号之一。现在,微软可以用Phi-2来复制或超越Llama的成功。
微软研究院ML基金会团队负责人Sebastien Bubeck表示,Phi-2是需要微调的完美模型。希望利用生成人工智能模型的小企业或初创公司可能会发现这是有益的。
Predelo数据科学副总裁Mark Tenenholtz表示:“我相信,有很多小型人工智能产品使用了像Llama这样的非商业LLM。Phi-2将取代所有这些。”
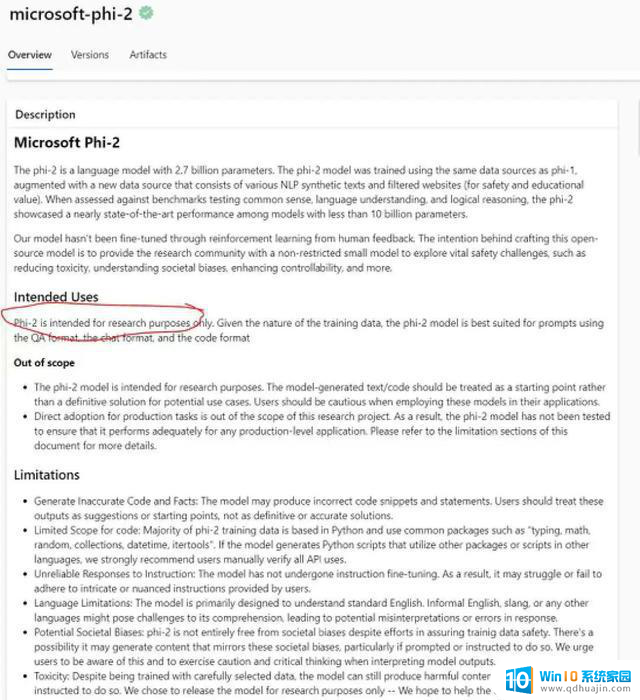
5、有限的“开源”在主题演讲中,Nadella演讲中表示:“Phi-2是开源的,很快就会出现在微软的服务模式目录中。”然而,快速浏览许可证就会发现,该模型目前仅用于研究目的。许多X(以前的Twitter)用户也指出了同样的观点。
图片
“开源仅用于研究目的”这话是不是很熟悉,让人想起早期的Llama版本。今年2月,Meta在非商业许可下与研究界分享了Llama的模型权重。然而,它后来在4Chan上以可接近的重量出现,无意中使其可用于商业用途。
如果微软希望用Phi-2复制Llama的成功,它需要使该模型可用于商业用途。此外,随着时间的推移,“开源”的这个词也面临新的审视。尽管像LLaMA这样的模型被吹捧为开源,但一些人认为它们并不真正符合开源的定义,因为Meta没有披露他们训练中使用的数据集。
所以,这也许正是小模型在商业化前,一场“冲锋”的号角。
参考链接:https://analyticsindiamag.com/decoding-microsofts-open-source-play-what-theyre-really-after/
https://analyticsindiamag.com/microsofts-strategic-shift-embracing-smaller-language-models-with-phi-2/
https://mp.weixin.qq.com/s/6wS4Pv9adQDlcGtczVL2-Q
来源: 51CTO技术栈
微软战略大转变:拥抱小模型!如何助力企业创新发展?相关教程
热门推荐
微软资讯推荐
- 1 两部门支持前沿技术基础研究,加强CPU和人工智能服务器攻关:市场重大事件
- 2 AMD下代GPU内部代号gfx13对应变形金刚角色曝光
- 3 win10磁盘管理器在怎么打开?有三种方法,快速学会!
- 4 如何解决Windows本身成为电脑性能瓶颈的问题?
- 5 女生必看!Windows 触控板神操作,让你电脑操作飞起,操作技巧大揭秘
- 6 Win10 微软账号转本地账号教程!最详细步骤分享
- 7 Win11废了我4TB数据 教你屏蔽Win11更新 非注册表法,如何保护电脑数据不被Win11更新影响
- 8 LLVM 21.1稳定版发布:新增AMD GFX1250支持,GB10编译选项优化
- 9 英伟达50系显卡创收破纪录 单季度43亿美元:英伟达显卡创收创新高
- 10 别再装双系统!WSL让Windows 11变万能,Linux应用直装2022最新版
win10系统推荐
- 1 萝卜家园ghost win10 64位家庭版镜像下载v2023.04
- 2 技术员联盟ghost win10 32位旗舰安装版下载v2023.04
- 3 深度技术ghost win10 64位官方免激活版下载v2023.04
- 4 番茄花园ghost win10 32位稳定安全版本下载v2023.04
- 5 戴尔笔记本ghost win10 64位原版精简版下载v2023.04
- 6 深度极速ghost win10 64位永久激活正式版下载v2023.04
- 7 惠普笔记本ghost win10 64位稳定家庭版下载v2023.04
- 8 电脑公司ghost win10 32位稳定原版下载v2023.04
- 9 番茄花园ghost win10 64位官方正式版下载v2023.04
- 10 风林火山ghost win10 64位免费专业版下载v2023.04
系统教程推荐