AMD中国式超车 从一座“百强县”开始:探索中国AMD的崛起之路

AMD-清醒异构人工智能应用联合实验室落户浙江
作者/ IT时报记者 郝俊慧
编辑/ 孙妍
“产业界似乎都执着于开发预算超千万的大模型,却少有针对中小企业算力需求的解决方案。我们希望能和一些中小企业合作,帮助建立企业自己的模型,从而真正让人工智能成为生产力提升的新动能。”11月22日,AMD高级副总裁、大中华区总裁潘晓明出现在浙江宁波慈溪的杭州湾大酒店,参加AMD-清醒异构人工智能应用联合实验室揭牌仪式。

同日,清醒异构和宁波芯向荣公司共同推出基于AMD MI210 AI卡和EPYC(霄龙)CPU处理器搭建的数据中心解决方案——慈溪“田园一号”智算系统,为慈溪本地企业提供多种行业应用场景人工智能解决方案。
这是一个清晰的信号。
当大模型之争进入下半场,越来越多的创业公司将目光投向更长尾的大模型微调和AI推理赛道,并与正准备在人工智能这轮技术新革命中摩拳擦掌的地方政府一拍即合,而AMD则抓住时机,加速在市场空档中提前“卡位”。

三年打造“百模慈溪”
AMD中国掌门人出现在慈溪,并不令人意外。
尽管只是宁波代管的县级市,但在国信中小城市指数研究院刚刚公布的“2023年全国百强县”中,慈溪名列第六,浙江省内排名首位。汽车零部件、智能小家电、化纤是这座县级市的主要特色产业集群,1361平方公里辖区内拥有至少600家年产值超过亿元的企业,其中,国家级专精特新“小巨人”企业数量超过20家,在长三角百强县中位居第一。
“很多慈溪企业正进入交接班时期,新上任的‘创二代’基本都是高学历,对智能制造、人工智能等新技术非常感兴趣,也希望向数字化要效益。”一位慈溪当地企业家告诉《IT时报》记者,对于ChatGPT、AIGC、大模型等话题,大家普遍很感兴趣,但也困惑于其实际落地应用,不知该如何从这次技术革命中获得“红利”。
对于AI产业链而言,有灵气、有活力、有实力的慈溪,是最好的试验田。
ChatGPT爆火一年之后,业内普遍形成的共识是。如果大模型的技术和业务始终是“两张皮”,很难真正为产业创造价值,必须在通用大模型基础上做小模型,让企业基于行业大模型,对自身数据进行精调,建构企业专属模型,打造高可用性的智能服务,形成企业自己的AI Agent(人工智能代理),才能真正融合技术和业务。
清醒异构此次推出的智能计算产品ML Base(被子),对标微软开源的分布式训练框架DeepSpeed,可以通过多种技术手段提高大模型训练的效率和可扩展性,从而帮助企业快速拥有自己的小模型,实现降本增效,享受人工智能带来的生产力跃迁。

“我们希望用三年时间打造‘慈溪百模’,为慈溪100家企业定制大模型,将慈溪打造为智慧工业的桥头堡。”清醒异构创始人余腾告诉《IT时报》记者,将与合作伙伴一起,推动慈溪成为大模型推动产业发展的AI时代新城市样本。
AMD是这个目标的算力底座。为“百模企业”部署大模型的“田园一号”智算系统,采用了全套AMD架构,其服务器+基础工具链+大模型的模式,在国内AMD生态中尚属首例。

Plan B 迎来起飞
对于已经 “厌倦”英伟达一家独大的中国AI产业链而言,AMD是个不错的Plan B。
作为产品线最为丰富的芯片厂商,AMD在CPU和GPU均有布局。也是为数不多能够生产出可用于训练和部署AI芯片的公司之一,有着被认为可与英伟达H100一较高低的算力芯片Instinct MI300 X,全球最快的超算——美国橡树岭国家实验室的Frontier同样基于AMD芯片。

但在今年之前,这个Plan B计划并没有那么迫切。因训练ChatGPT而成为“当红炸子鸡”的英伟达,一度成为国产互联网大厂训练大模型的必选。国内鲜有搭载AMD GPU芯片的国产算力服务器。
然而,在不断变化的国际复杂形势下,“将鸡蛋放在同一个篮子里”充满了不确定性。今年以来,微软、甲骨文、IBM等国际厂商,表现出对AMD的浓厚兴趣,国内服务器厂商也开始布局AMD GPU。
作为算力底座,一台专用于人工智能训练推理的AI服务器由CPU、GPU、硬盘、内存等来自全球不同厂商的零部件组成,每次核心部件的更新,都要进行漫长的适配和调试。
兼容性、性能、生态是服务器厂商面临的三大挑战。“如何让服务器的结构性能实现最优化?如何用更有性价比的方案实现预期需求?如何能够以最低的成本将应用跑起来?”这“三连问”天津服务器厂商思腾合力客户成功部总监徐振宇一直在思考的。
“至少需要三个月。”余腾告诉《IT时报》记者。今年3月,清醒异构开始调试基于AMD架构的AI服务器主机。
11月10日举行的第五届中国超级算力大会上,清醒异构的两台主机TsingLand-1A系统一号和二号双双挺进前十,分别位列第七位和第八位。尽管并没有透露这两台主机的具体价格,但余腾表示,对标英伟达A100的性能,TsingLand-1A性价比优势十分明显。
仅从芯片价格来看,《IT时报》记者查询到,A100报价16万元,MI 210报价为8.4万元,约为前者的50%。
不过,受限于今年10月17日美国升级版禁令,仍能在国内销售的MI210算力并不算强劲。
“从训练的角度来看,MI210略显吃力,毕竟算力有限,但在大模型微调和推理方面,它的性价比非常不错。”余腾告诉记者,通常情况下,人工智能工作负载包含大模型训练推理、基础模型的微调和概率推理,“田园一号”更适合后两者,尤其是中国企业对于数据的隐私性更为关注,大模型的私有化部署很可能成为主流。
AMD官网显示,MI210的半精度 (FP16) 性能181 TFLOPs(每秒万亿次浮点运算),单精度 Matrix (FP32) 峰值性能可达45.3 TFLOPS,专用显存为64 GB。余腾介绍,单片MI210可装入一个数十亿参数的开源大模型或者一个已经训练好的行业大模型,一台八卡服务器可以同时为八家企业提供服务。
对比英伟达即将针对中国市场推出的“改良版”H20,半精度 (FP16) 性能为148TFLOPS(每秒万亿次浮点运算),虽然增加了一颗HBM3(高性能内存)到96GB,但成本随之增加240美元。尽管还未公布,但业内人士普遍预估搭载八卡H20的服务器价格或在百万元以上,和禁令前的A100大体相当。
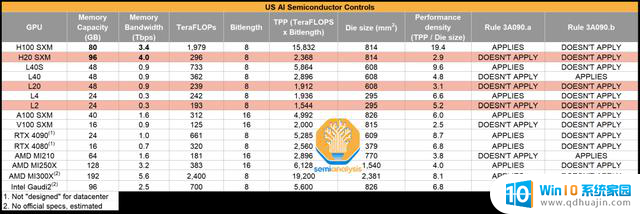
AI芯片性能对比,图源:semi analysis
至少从目前看,MI210的性价比不错,更重要的是有产能。“我们从供应链伙伴那里了解到,AMD在台积电的产能有一定保证,因此决定All in AMD。”余腾表示。
2023年Q3财报显示,AMD的霄龙CPU产品组合的销售推动数据中心营收环比增长21%,即将正式交付的MI 300X被认为将是AMD最快突破10亿美元销售额的产品。

跨越CUDA生态
任何一个对英伟达提出挑战的厂商,都要跨过CUDA。
作为英伟达围绕硬件修建的护城河,其发展17年的并行计算和编程平台CUDA赢得了绝大多数算法工程师的心。AMD也有类似的平台——ROCm,但却比CUDA来得晚了十年,且此前只支持Linux。“除了AMD自己的工程师,国内懂ROCm的可能不超过1000人。”一位算法工程师告诉记者。
不过,近两年,形势正在发生变化。中信证券一份研报显示,2023年4月,AMD推出的ROCm5.6 版本已经形成了底层驱动/运行时、编程模型、编译器与测试调试工具、计算库、部署工具等相对清晰的软件架构,对比 CUDA,在开发、分析工具、基础运算库、深度学习库与框架、系统软件方面做到相对完整的支持。目前,整个 ROCm 项目的源代码基本已经全部公布于 GitHub。
今年7月,AMD正式推出HIP SDK,可以将CUDA 应用转为简化的C++代码,从而使其更容易地编译并运行在AMD或NVIDIA GPU上。也就是说,无需寻求AMD的技术支持即可将 GPU 加速图形和仿真工具移植到AMD硬件中。
近日,AMD收购了一家名为Nod.ai的开源AI软件研发公司,拓展其在开源AI软件方面的实力。Nod.ai成立于2013年,为大型数据中心运营商和其他客户提供AI解决方案,部署针对AMD硬件进行优化的高性能人工智能模型。
某种程度上,清醒异构的功能类似Nod.ai。
徐振宇透露,清醒异构此次发布的MLbase,作为基础软件工具链产品可以封装AMD ROCm,在思腾合力和清醒异构合作的服务器方案中,6种可拓展的Polybench评测程序在AMD系统上从单核到128核逐步使用测试可见,通过并行优化可以直接释放系统40~60倍的算力。同时,习惯于CUDA的开发者可以在不改动代码的前提下,将大模型直接从基于英伟达芯片的服务器上迁移至AMD芯片服务器上,整个过程不到半小时,而且代码零改动。
生成式AI研发公司生数科技市场总监纪林依告诉《IT时报》记者,生数大模型已经针对AMD芯片进行了适配跟迁移,“以较低的迁移成本和较小的精度损耗,实现了较好的模型效果。”
“对于企业而言,算力就是算力,而无需考虑它来自哪颗‘芯’。”余腾表示。
事实上,慈溪的这场发布会,更像是一场“清华系”的聚会。清醒异构、医者AI、生数科技、共绩算力、清昴智能……上台宣讲者均来自清华系创业公司。现场由清华大学学生创业协会宣讲其发起组织的第二届“清醒杯”全国高校人工智能与大模型创新创业挑战赛:这次大赛由AMD提供算力基座,采用清醒异构和清昴智能的工具链对参赛项目进行底层优化和模型适配。预计吸引50所全国高校参与,吸纳300~500个报名项目,吸引3000名人工智能相关行业人才参与。
高校往往是企业打造生态阵线的第一站,AMD将首站选在了潘晓明的母校——清华大学,中国人工智能产学研一体化的摇篮。潘晓明也透露,除了清华,目前也在接洽国内其他985高校,对方对AMD算力基座非常感兴趣。
“如雨后春笋。”某服务器厂商如此形容当前国内的AMD生态。
日益收紧的禁令、翻着跟头涨价的算力,促使国内AI公司开始寻找Plan B,甚至Plan C,多元算力平台的构建成为必然。
AI大幕刚刚拉开,算力赛道上,群雄环伺。
排版/ 季嘉颖
图片/ IT时报 东方IC semi analysis
来源/《IT时报》公众号vittimes
E N D

AMD中国式超车 从一座“百强县”开始:探索中国AMD的崛起之路相关教程
热门推荐
微软资讯推荐
- 1 两部门支持前沿技术基础研究,加强CPU和人工智能服务器攻关:市场重大事件
- 2 AMD下代GPU内部代号gfx13对应变形金刚角色曝光
- 3 win10磁盘管理器在怎么打开?有三种方法,快速学会!
- 4 如何解决Windows本身成为电脑性能瓶颈的问题?
- 5 女生必看!Windows 触控板神操作,让你电脑操作飞起,操作技巧大揭秘
- 6 Win10 微软账号转本地账号教程!最详细步骤分享
- 7 Win11废了我4TB数据 教你屏蔽Win11更新 非注册表法,如何保护电脑数据不被Win11更新影响
- 8 LLVM 21.1稳定版发布:新增AMD GFX1250支持,GB10编译选项优化
- 9 英伟达50系显卡创收破纪录 单季度43亿美元:英伟达显卡创收创新高
- 10 别再装双系统!WSL让Windows 11变万能,Linux应用直装2022最新版
win10系统推荐
- 1 萝卜家园ghost win10 64位家庭版镜像下载v2023.04
- 2 技术员联盟ghost win10 32位旗舰安装版下载v2023.04
- 3 深度技术ghost win10 64位官方免激活版下载v2023.04
- 4 番茄花园ghost win10 32位稳定安全版本下载v2023.04
- 5 戴尔笔记本ghost win10 64位原版精简版下载v2023.04
- 6 深度极速ghost win10 64位永久激活正式版下载v2023.04
- 7 惠普笔记本ghost win10 64位稳定家庭版下载v2023.04
- 8 电脑公司ghost win10 32位稳定原版下载v2023.04
- 9 番茄花园ghost win10 64位官方正式版下载v2023.04
- 10 风林火山ghost win10 64位免费专业版下载v2023.04
系统教程推荐